This page archives the formal model accompanying the publications:
Gidon Ernst, Gerhard Schellhorn, Dominik Haneberg, Jörg Pfähler, and Wolfgang Reif: A Formal Model of a Virtual Filesystem Switch. In Proc. of SSV 2012, Sydney, Australia. SSV 2012
Gidon Ernst, Gerhard Schellhorn, Dominik Haneberg, Jörg Pfähler, and Wolfgang Reif: Verification of a Virtual Filesystem Switch. In Proc. VSTTE 2013, Atherton, USA. VSTTE 2013
J. Pfähler, G. Ernst, G. Schellhorn, D. Haneberg, and W. Reif: Formal Specification of an Erase Block Management Layer for Flash Memory. In Proc. HVC 2013, Haifa, Israel. HVC 2013
Back to the main site.
This page describes the KIV projects, specifications and proofs of the different layers in the construction of a verified Flash file system, notably the AFS and VFS layers described in A Formal Model of a Virtual Filesystem Switch [1] (with some small modifications), and the POSIX model + refinement proof described in Verification of a Virtual Filesystem Switch [2].
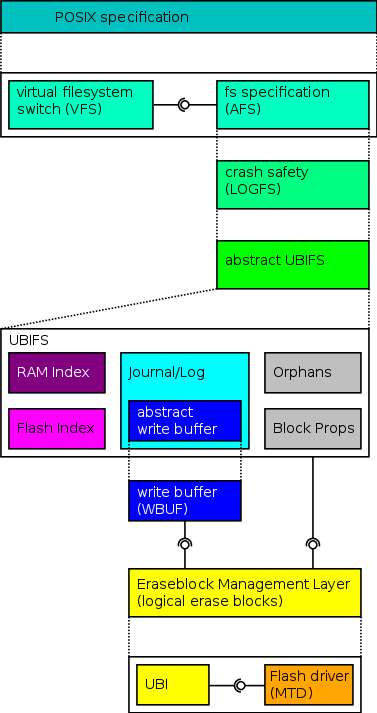
The effort is structured into layers that are connected by refinement, corresponding to the various logical parts of the file system. The top level is an abstract formal model of the file system interface as defined in the POSIX standard, serving as the specification of the functional requirements, i.e., what it means to create/remove a file/directory and how the contents of files are accessed.
The POSIX specification is implemented by a combination of VFS (generic part) and AFS (operational specification of the file system specific parts). AFS is then further refined to an abstract model of the UBIFS file system, independently of VFS.
At the bottom, UBIFS relies on UBI to provide wear-leveling and Linux MTD as an interface to the hardware.
Click on the layers in the diagram on the left to get a short description of the respective formal model.
The POSIX specification defines an algebraic directory tree with an indirection for hard-links to files at the leaves.
Directories and files are accessed by paths. The operations considered are create, link, unlink, mkdir, rmdir, open, close, read, write, truncate, readmeta (corresponds to stat), setmeta (corresponds to chmod, chown, ...), rename, and readdir.
The Virtual Filesystem Switch realizes aspects common to all file systems, in particular path lookup, access permission checks, mapping of file content to pages, open file handles and orphaned files. It depends on a file system implementation (precisely, on an abstract description of file system behavior) to provide lower-level operations.
The abstract file system specification (AFS) defines the expected behavior of a file system implementation. Its operations roughly correspond to the POSIX level operations, however, the modifications are local and are defined in terms of inodes instead of paths.
The LOGFS specification introduces the conceptual separation of persistent data on flash memory and data stored in RAM to study the effect of power loss.
Abstract UBIFS introduces flash file system specific concepts, in particular flat indices for file system objects, accessed by keys.
The UBIFS model splits up further subcomponents, and introduces caching of several data structures, in particular, it maintains only a partial RAM index, and tracks the set of orphaned files.
The RAM index stores a (partial) mapping from keys to addresses of file system objects. The Flash index is an old copy of that information, created during the last commit.
Purpose of the Journal/LOG is to write file system objects to flash memory in a sequential fashion, and to deal with the fact that flash is structured into erase blocks. It has a subcomponent, the write buffer (given as abstract specification) that maps file system objects to their representation as byte arrays.
The orphan component stores a set of inode numbers that have been unlinked completely from the file system tree and must be deleted after the last file handle is closed. This information is updated incrementally and written to flash during commit.
Properties (logical) Blocks are implemented by this module, examples are the space that is free or used.
The write buffer implements write buffer functionality on top of the UBI interface.
The abstract UBI specification defines the interface through with flash memory is accessed by the upper layers. Blocks are addressed logically and can be written (append only), read (randomly), and erased (as a whole).
The UBI model links the UBI interface to the Flash driver. It implements the mapping from logical to physical erase blocks (which is updated transparently to the upper layers). Its main purpose is wear-leveling, i.e., to distribute erases evenly between all physical blocks of the flash medium.
The MTD model specifies the Linux memory technology device model. It represents the lowest level in our refinement chain and encodes all assumptions about the hardware and the driver implementation.
Data structures that are shared between projects are defined in a common library
⌊.⌋ into low-level errors, that may arise nondeterministically.The presentation in the publications is slightly different and some minor technical aspects have been neglected. Here is a list of the differences:
f[x,y] instead of f[x ↦ y], similarly tree update is written as t[p,t], allocation is ++, deallocation is --fdata is called mkfilefs or dirsSee here for an overview of the specifications in the POSIX project. At the top level is the definition of the Abstract State Machine posix-asm that contains all top-level operations as well as some helper procedures.
The algebraic directory tree is split up in the data-type definition, definition of accessors, and the function fids,
Precondition predicates are defined here.
The POSIX main invariant (called fids-cons) is defined in specification posix-base. Proofs for this invariant can be found here, in particular see posix-op-fids-cons.
See here for an overview of the specifications in the VFS project. At the top level is the definition of the Abstract State Machine vfs-asm that contains all top-level operations as well as some helper procedures.
Various functions and predicates are defined in vfs-base,
The state invariant of-cons: all open file handles point to valid files.
An abstraction of file content to a stream of bytes.
You can find all proofs about operations here.
See here for an overview of the specifications in the AFS project.
The two state variables dirs and files are defined as instances of heaps (i.e., partial functions), that map to dirs resp. files.
The ASM defines the AFS operations.
The specification afs-base defines
AFS operations (see below) are wrapped here to provide nondeterministic errors and precondition checking.
The refinement project is here.
Specification abs defines the abstraction functions, specification R aggregates invariants and abstraction into a predicate R. Various rewrite rules and theorems are lifted from the abstraction function (see here) to consequences of R (see here).
The latter ones are important for proof automation of the refinement proofs. Note that the proof for rename has not been completed yet, which we will do during the next days.
The proofs for read and write rely on invariants, defined here as predicates.
Finally, the generic refinement theory is instantiated, by showing the commuting diagrams, in particular this lemma.
The formal model can be found here. Basically, the AFS state is duplicated into a current version corresponding to the data in RAM, and an outdated version that represents the state of the last commit. Operations manipulate only the RAM state RDIRS, RFILES. The difference to the flash state is recorded in an append-only log LOGLI, which is a list of log entries. These correspond roughly to the different operations.
The main invariant is replay consistency. It specifies that the replay operation recovers the current RAM state from persistent data and the log, where replaying one log entry is a case distiction over the type of the entry, see here. Proofs for this invariant are here. They rely on a splitting lemma for replay, which in turn is established by several commutations.
The main difficulty of this model is to deal with orphaned files, which have been referenced by a file handle previously and must be deleted during the replay. Note that during commit, the current set of orphans is written to Flash.
Further functions and consistency invariants on the state are defined here
orphans denotes the set of orphaned files/directoriesorphans-cons, subdirs-cons and logli-cons are disjointness properties of different parts of the stateA more systematic description of this model is yet to be done.
The Eraseblock Management Layer model provides read, write and erase functionality on logical eraseblocks (LEBs). Furthermore, it supports asynchronous erasure via unmap. The project (see here for a graphical overview) is structured as follows:
The MTD model specifies the Linux memory technology device model. It represents the lowest level in our refinement chain and encodes all assumptions about the hardware and the driver implementation. The project (see here for a graphical overview) is structured as follows:
The existence of a trace that leaves the flash device unmodified is shown explicitly, see theorems ex-trace-op in the theorem base of specification mtd-asm.
The Unsorted Block Images layer consists of two projects.
The first project (see here for a graphical overview) is an abstract I/O layer (see specifications ubi-io-ops, ubi-io-inv, ubi-io-pre for operations, preconditions and invariants) responsible for en/decoding of EC/VID-headers. It splits the physical eraseblocks of MTD into three distinct data structures: the ec-headers, the vid-headers and the data area (see specifications aecheader, avidheader, apeb). Its state is an array APEBS of elements of type apeb. The implementation of this I/O layer (see specifications ubi-io-impl, echeader, vidheader, data-conv for the data structures and conversion operations) uses the MTD operations. For reads several retries are attempted. The refinement between the abstract I/O specification and the implementation is proven in specifications abs and refinement. The abstraction relates any bad abstract erase block to a bad concrete erase block, because bad blocks are not read/written to and the contents of the abstract erase block therefore may be arbitrary.
Again, existence of a trace that leaves the state unmodified is shown explicitly, see theorems ex-trace-op in the theorem base of specification ubi-io-ops.
The second project (see here for a graphical overview) consists of the UBI implementation on top of the abstract I/O layer. The operations are implemented in specification ubi-ops. The UBI state consists of
in addition to the state APEBS of the abstract I/O layer. The wear-leveling array is used to store a status (free, used, erasing, erroneous) for each PEB and caches the erase counter of a good PEB. Invariants are specified in ubi-base. The crucial invariants are:
Additional predicates are used to specify that the PEB containing the volume table matches the current in-RAM mapping (valid-vtbl) and constrain the erase queue (three types of valid-eraseq). The predicate ubi-cons(APEBS, VOLS, WLARRAY, ERASEQ, VTBLPNUM, SQNUM) is defined as equivalent to the conjunction of all invariants.
It proved easier to use a multiset of sequence numbers to specify uniqueness and maximality of them uniformly. The function valid-sqns(v, l, APEBS) (see specification sqns is defined recursively over APEBS and returns the multiset of all sequence numbers of valid PEBs. Validity is defined in specification valid-peb
The operation to format an initial device as well as the recovery from an unexpected power failure are defined in specification ubi-recover. The operation format is the initialization operation, which writes headers to each PEB and writes an initial version of a volume table without any preexisting volumes.
The invariant proofs for each normal operations is in the theorem base of specification ubi-ops.
The main correctness theorem crash-recover about the recovery can be found in specification ubi-crash-recovery. It asserts that after a crash and subsequent recovery, a state is reached, which
The refinement is in the project ubi-refines-ebm.
The abstraction relation is defined in specification abs and the refinement proofs in the specification refinement.
The refinement between the recovery operations is proven in specification crash-recovery. The theorem basically follows directly from the above observations.
Download from here.
The Simulation code is in src/de/uniaugsburg/flashix/:
fuse contains the glue codecommon provides some data typesvfs implements the VFS layer on top of afsposix defines a POSIX-like interface as a Scala-TraitNote that the package might be slightly out of sync with the formal models.
The main class is
de.uniaugsburg.flashix.fuse.MountScala (tested with version 2.9.2)
Fuse (tested with version 2.9.1)
Fuse-J (tested with version 2.4-prerelease1)
Included as lib/fuse-j.jar.
Native library only included for x86_64 (sorry).
To build the native library for ix86, download the package from http://sourceforge.net/projects/fuse-j/ as well as the fuse development package. Compile it (ant) and copy
./jni/libjavafs.soto lib (or lib64 on 64 bit machines, the correct one will be picked automatically).
fuse-j-2.4-prerelease1 has a compile bug with Java 7. You can copy the updated build script files in folder "patch" and the patch to the jni subfolder of fuse to work around this issue.
./build.sh./run <mountpoint> [-d]where
fusermount -u <mountpoint>removes the mount (and terminates the simulation). Please note that it's not the other way round, i.e., killing the simulation does not unmount.