


![]()
The Flashix project aims at the construction and verification of a state-of-the-art file system for flash memory. This page provides an overview and details of the formal development. We describe the formal models, specifications and implementation layers. The development is done using the KIV Verification System.
Please also see the website of the project at the Institute for Software & Systems Engineering (ISSE), University of Augsburg. © 2015-2017, all rights reserved.
This work is part of the project Verifcation of Flash File Systems (orig. Verifikation von Flash-Dateisystemen, RE828/13-1 and RE828/13-2, DFG/German Research Council).
Current researchers: Prof. Dr. Wolfgang Reif, Jörg Pfähler, Stefan Bodenmüller, Dr. Gerhard Schellhorn,
Previous researchers: Dr. Gidon Ernst, Dr. Dominik Haneberg.
Students: Andreas Schierl, Andreas Sabitzer, Berthold Stoll, Jessica Tretter, Maxim Muzalyov, Michael Pini, Patricia Kaufmann, Sarah Edenhofer, Dominik Mastaller, Ayleen Schinko, and Timo Hochberger.
The material on this web-site represents (excerpts of) ongoing work. It is to be understood as documentation of the project. Thereby, we do not provide any support and warranties whatsoever. You can use the material or excerpts of it for personal information and experimentation; and communication with others in unmodified form as long as attribution to the authors (current researchers), institute, university, and DFG project identification is included.
If you use this material, be sure to understand the assumptions and conditions under which the verification has been conducted (see below). The word "guarantee" below must always be understood relative to the assumptions.
Please contact the team if you want to contribute. We're looking for cooperations. If you think that your research may interest us, is related, or neglected in our citations, please feel free to contact us as well.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
We provide short-cuts to the complete material available here. For a description see below.
The project is rather complete. Currently, the only missing feature that remains to be verified is efficient indexing with B+-trees. For better efficiency, we are also currently working on improved caches throughout the file system and concurrency for background operations such as garbage collection and wear-leveling.
Previous versions of some of the models and proofs that have been published alongside some of the papers are available as well:
There are four primary conceptual layers.

Fig. 1: High-level structure
As a basis for the concepts necessary we use the flash file system UBIFS, that was integrated into the official Linux kernel in 2008.
We follow a correctness-by-construction approach, namely by incremental refinement from an abstract description of the POSIX file system interface down to executable code. Conceptually, the main refinement steps involve mapping paths as found in the POSIX layer to Inodes (similar to VFS in Linux), introduction of index data structures for persistent/cached file system objects towards the actual erase blocks, using an indirection from logical blocks to support wear-leveling (similar to the UBI layer in UBIFS).
We provide the following guarantees:
We make the following assumptions about the hardware:
Furthermore, we assume that that the KIV theorem prover, the code generator and the compiler are correct, and that the hardware/driver implements our specification (or at least that we do not exploit incorrect behavior). Note that we consider it an orthogonal aspect to verify the generated code or the generator itself (and we have not done this). The challenges addressed in this project lie in the algorithms, in particular the ones for recovery after errors and power-cuts.
We are currently working towards increasing the performance of the file system by
Figure 2 shows an overview over the components in the file system. Click on these for a short (informal) description, and a link to the respective specification and implementation. Note that not all formal models are depicted individually in the picture.
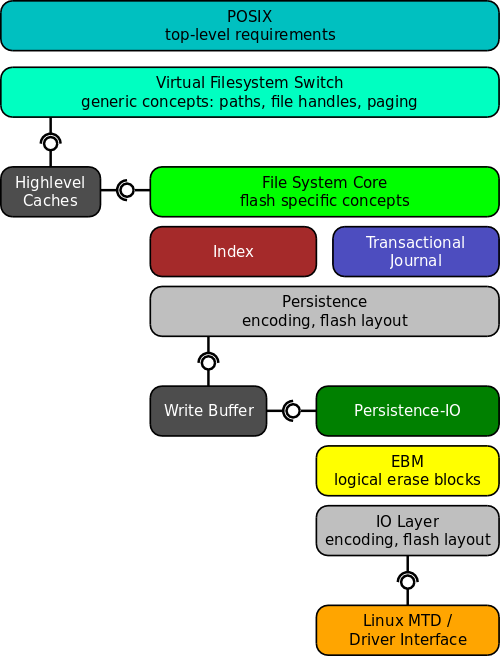
Click on the layers in the diagram on the left to get a short description of the respective formal model.
Operations op in the signature are written as
op (in1, ..., inn; inout1, ..., inoutm)with input parameters in1, ..., inn and input/output (reference) parameters inout1, ..., inoutm separated by a semicolon ;.
The state of each layer is a vector of (typed) variables
x: TThe POSIX specification defines an algebraic directory tree with an indirection for hard-links to files at the leaves. Directories and files are accessed by paths.
Signature:
format (md)
create (path, metadata)
mkdir (path, metadata)
link (path, path')
unlink (path)
rmdir (path)
open (path; fd)
close (fd)
read (fd, len; buf)
write (fd, buf; len)
truncate (path, size)
readmeta (path; md)
writemeta (path, md)
rename (path, path')
readdir (path; names)
fsync (path)State:
tree: directory-tree
fs: fid → file
of: fd → handleThe Virtual Filesystem Switch realizes aspects common to all file systems, in particular path lookup, access permission checks, mapping of file content to pages, open file handles and orphaned files. The VFS implements the POSIX interface and thereby has the same set of operations. It depends on a file system implementation (precisely, on an abstract description AFS of file system behavior) to provide lower-level operations.
VFS State:
of: fd → handleAFS State:
dirs: ino → dir
files: ino → fileFormal Specification
Implementation
AFS Specification
Abstraction Relation
Refinement Proofs
A Cache layer was integrated between the VFS and the File System Core to improve performance. It contains three caches for highlevel objects (inodes, dentries and pages). These caches can either be operated in full write-through (all writes go directly to flash) or partially in write-back mode (writes of pages and metadata are deferred to toplevel fsync calls).
State:
icache: ino → inode
dcache: ino × name → dentry
pcache: ino × pageno → pageTo simplify verification the Cache layer is built on the abstract specification of the File System Core, namely the AFS. The layer is implemented as a decorator and hence it has the same signature as the File System Core repectively the AFS. While the functional correctness of the Cache layer has already been proved, the verification of Crash-Safety for caching in write-back mode is yet to come.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The Core of the File System introduces flash specific concepts namely out-of-place updates and indexing. The provided operations correspond almost 1:1 to the POSIX operations, except that they are defined locally (paths are already traversed).
Signature:
create ( ; inode, dentry)
...The state consists of a current RAM Index ri, an outdated flash index fi, an unodered store of file system objects (called nodes) fs and a log. Furthermore, so-called orphans (files that are still in use but unreachable from the directory tree) need to be recorded.
ri, fi: key → address
fs: address → node
log: List[address]
ro, fo: Set[key]This state is a simple, abstract view of the core concepts. The actual data structures implementing these variables are given in the two subcomponents index and journal.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The RAM index stores a (partial) mapping from keys to addresses of file system objects. It is implemented as a B+ tree ultimtately (which means that special care has to be taken to prevent allocation failures at inconvenient times). The index provides some advanced functions that iterate over entries of directories resp. pages of a file.
Signature:
newino (; key)
contains (key; exists)
lookup (key; exists, adr)
store (key, adr; oldadr)
delete (key; oldadr)
truncate (key, n; oldadrs)
entries (key; keys)
commit()
recover()The Flash index is an old copy of that information, created during the last commit. Recovery restores the last flash index.
State:
root: reference
rootadr: address
heap: HeapThe RAM index is represented by a pointer root to the root node of the B+ tree. The Flash index is represented by the (flash) address of the encoded root node.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
Purpose of the Journal/Log is to write groups of file system objects to flash memory in a sequential fashion, and to deal with the fact that flash is structured into erase blocks. The purpose of the journal is twofold
Signature:
get(adr; node)
add_n(node_1, ..., node_n; adr_1, ..., adr_n)
gc()State:
journal-head-valid: bool
sqnum: nat
sync: boolIf the sync flag is set the journal flushes all caches on every add operation. Otherwise the writes are cached.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The persistence layer is the interface that changes to a block and byte-based representation. It provides the means to access all group and index nodes. It relies on the write buffer to cache partial written flash pages.
Signature:
add_group_nodes (groupnodes; addresses)
read_group_node (address; groupnode)
read_group_block (block; addresses, groupnodes)
add_index_node (indexnode; address)
read_index_node (address; indexnode)
get_gc_block (; block)
(de)allocate_group/index_block()
sync()
commit(rootadr)The commit operation writes the address of the new flash index and all other internal data structures atomically.
State:
lpt: Array[lptentry]
freelist: List[nat]
gcheap: Binheap[(ReferencedSize, Block)]The gcheap stores the used eraseblocks in combination with the number of bytes in the erase block that are still referenced by the RAM index. This is used to retrieve a suitable block for garbage collection with the minimum number of bytes still referenced by the index.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The write buffer implements write buffer functionality on top of the persistence-io interface. Since flash memory can generally be only written at page granularity, the write buffer caches partially written pages. It provides an interface that is very similar to the hardware (MTD) and to the erase block management (EBM), however, erasing is always done asynchronously via the unmap operation, or, in case the logical block is immediately reused, by remap. There is no flush operation - writing up to a page boundary is sufficient.
Signature:
move_buf (block, offset)
write_buf (bytes, buf)
destroy_buf ()
read (block, offset, len; buf)
remap (block)
unmap (block)State:
bufblock: Option[nat]
wbuf: (buffer, offset, written)The variable bufblock stores which erase block (if any) is currently buffered and wbuf contains the page-sized buffer, the offset in the erase block the buffer starts at and the number of bytes stored in the write buffer.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The persistence I/O model encodes several internal data structures (that were introduced in a in-RAM form in the persistence model) on flash. These include an on-flash version of the LPT (used to store block properties such as free/used size), the list of blocks that form the log, the flash orphans and the superblock. All these data structures are written atomically during a commit operation.
In the event of a power failure the recover procedure restores all these data structures and returns them for the recovery of upper models.
Signature:
add_log_block (block)
read_log(; blocks)
commit (lpt, rootaddress, orphans)
recover(; lpt, rootaddress, orphans)Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The Erase Block Management layer defines the interface through with flash memory is accessed by the upper layers. Blocks are addressed logically and can be written (append only), read (randomly), and erased synchronously or asynchronously (as a whole).
The implementation links to the interface to the Flash driver. It implements the mapping from logical to physical erase blocks (which is updated transparently to the upper layers). Its main purpose is wear-leveling, i.e., to distribute erases evenly between all physical blocks of the flash medium. It furthermore implements simple volume management (omitted in the signature).
Signature:
read (block, offset, len; buf)
write (block, offset, len, buf)
erase (block)
map (block)
unmap (block)
change (block, len, buf)Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The EBM IO layer is a simple interface that is responsible to encode/decode all information that the EBM implementation stores on flash other than user-data, such as block headers, which contain an inverse mapping to logical blocks.
Formal Specification
Implementation
Abstraction Relation
Refinement Proofs
The MTD model specifies the Linux memory technology device model. It represents the lowest level in our refinement chain and encodes all assumptions about the hardware and the driver implementation.
Signature:
read (block, off, boff, len; buf)
write (block, off, boff, len, buf)
erase (block)
mark_bad (block)
is_bad (block; flag)
page_size (; pagesize)
peb_size (; pebsize)
block_count (; n)State:
pebs: Array[(Array[Byte], fill, bad)]We have conducted initial tests with the SibylFS file system conformance checker. See the results. Please note that we have only included the HTML output, not the traces themselves (which are quite big) so the sexp, stdout, and stderr links will be dead.
Remarks on the Results: Currently, the flashix file system has a minor defect related to hard links to directories, which are not listed properly. This is a known problem and will be fixed soon. For this reason some of the tests fail.
Furthermore, almost all of the permission tests are fatally aborted, presumably during test setup. This seems to be an issue with the test environment, which does not permit the creation of temporary user accounts for the test suite.
"WARNING!!! Executing test scripts directly on your machine has the potential to destroy your data." Read the SibylFS documentation first, in particular this page, before you run the commands below.
Replace /mnt/flashix and the output folder 2015-12-14_wLc with the values for your test setup. Mount the flashix file system with
$ flashix /mnt/flashixIt will not fork to background currently but instead show you a whole lot of debug information. In another terminal execute
$ fs_test exec --model path=/mnt/flashix/ --suites test-suite 2> exec.err.md
$ fs_test check linux_spec 2015-12-14_wLc 2> check.err.md
$ fs_test html 2015-12-14_wLc